Introduction
Apache Kafka is a highly scalable, distributed streaming platform designed to handle real-time data feeds. It has become a cornerstone of many big data and event streaming applications, thanks to its high throughput, fault tolerance, and scalability. This blog post aims to delve into the architecture of Kafka, covering its core components, how it works, and its applications in real-world scenarios.
Core Components of Kafka Architecture

Producers and Consumers
At the heart of Kafka’s architecture are producers and consumers.
Producers are the applications or machines that publish events or messages to Kafka topics. They can write messages to multiple topics and choose the partition to which the message is to be written based on various strategies, including the message’s properties or Kafka’s default partitioning strategy.
Consumers, on the other hand, are the applications or machines that subscribe to topics and process the published message feeds. They read messages, using offsets to track which messages have been consumed. Consumers can operate as part of a group, enabling scalable and fault-tolerant processing of messages.
Topics and Partitions
Kafka organizes data into topics, which are categories or feeds of messages. Topics are divided into partitions to allow for parallelism and scalability. Each message within a partition is an ordered, immutable sequence of bytes. Producers write messages to specific partitions, and consumers read from these partitions. The choice of partition can affect the order in which messages are consumed, but Kafka ensures that messages within a partition are always read in order.
Brokers
Brokers are the nodes in Kafka that store the topics and partitions. Each broker can store multiple topics and partitions, and the data is distributed across all the brokers in a Kafka cluster. This distribution allows Kafka to handle high volumes of data and provide fault tolerance. If a broker fails, the data is not lost, as it is replicated across other brokers in the cluster.
ZooKeeper
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. Kafka uses ZooKeeper to manage and coordinate the Kafka brokers. It is essential for Kafka’s operation, as it keeps track of the state of the cluster, such as which broker is the leader for each partition.
In newer versions of kakfa, zookeeper is not needed, Kafka uses raft (Raft Consensus Algorithm).
Reading Strategies in Kafka
Kafka supports different reading strategies to ensure data integrity and performance:
At most once
At-most-once semantics occur if the producer doesn’t retry on ack timeouts or errors. This might result in messages not being written to the Kafka topic and hence not delivered to the consumer. It’s a trade-off to avoid duplication, even though some messages might not make it through.
At least once
At-least-once semantics mean a message is written once to the Kafka topic if the producer gets an acknowledgment (ack) from the broker with acks=all. But, if there’s a timeout or error, the producer might retry, risking duplicate messages if the broker failed after acknowledgment but before writing to the topic. This can lead to duplicated work and incorrect results, despite the good intention.
Exactly once
Exactly-once semantics ensure that a message is delivered precisely once to the end consumer, even if the producer retries.
To read more about delivery semantics, check this blog : Exactly-once Semantics is Possible: Here’s How Apache Kafka Does it (confluent.io)
Kafka’s Applications and Adoption
Kafka’s architecture and features make it suitable for a wide range of applications, from real-time analytics and monitoring to log aggregation and event sourcing.
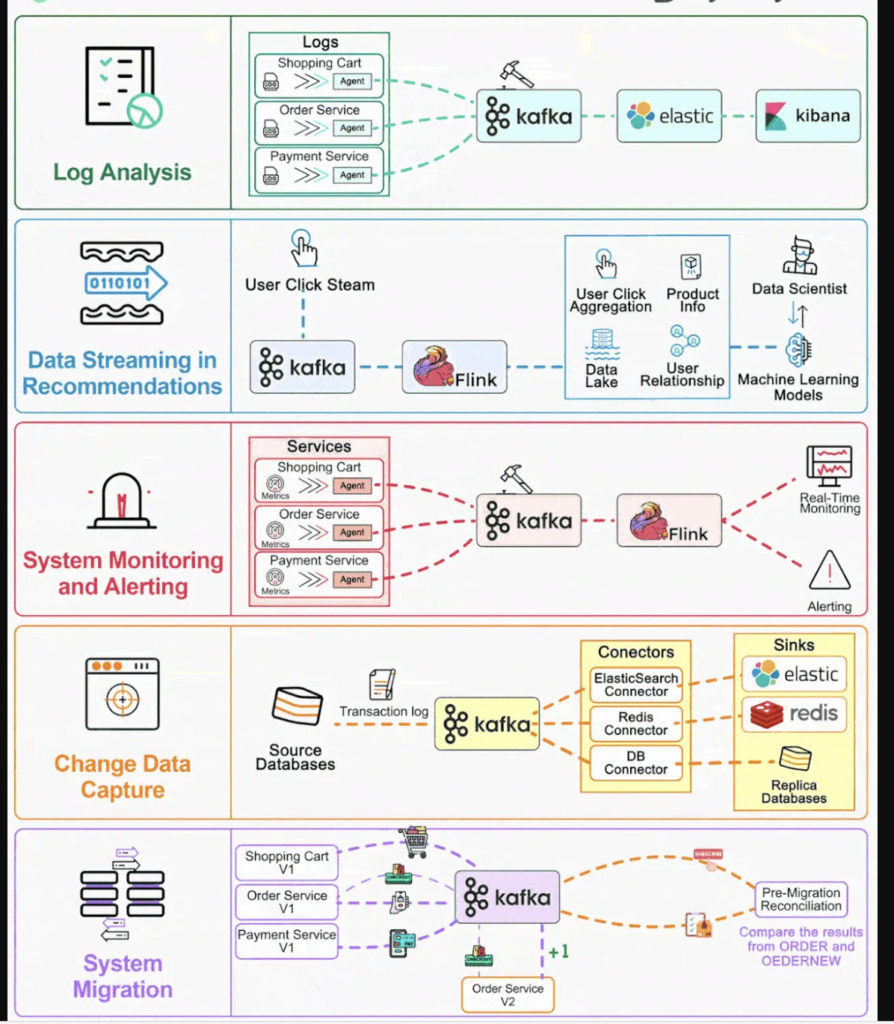
Conclusion
Apache Kafka’s architecture, centered around producers, consumers, topics, partitions, brokers, and ZooKeeper, enables it to handle massive volumes of data in real-time. Its support for different reading strategies ensures data integrity and performance, making it a powerful tool for big data and event streaming applications