The recent release of DeepSeek R1 has generated significant buzz in the AI community. While much of the discussion has centered on its performance relative to models like OpenAI’s GPT-4 and Anthropic’s Claude, the real breakthrough lies in the underlying algorithmic innovations that make DeepSeek R1 both highly efficient and cost-effective. This post explores the key technical advancements that power DeepSeek’s latest model.
Model Architecture and Training
DeepSeek R1 is part of a broader model ecosystem, and it’s essential to distinguish between two key models:
- DeepSeek V3: A general-purpose base model, released in December, comparable to GPT-4o and Gemini 1.5.
- DeepSeek R1: A reasoning-optimized model, built on top of V3, specifically designed for complex problem-solving.
While R1 does not introduce a radically new architecture, it employs a strategic combination of advanced techniques to enhance reasoning efficiency. Many of these innovations were previously discussed in DeepSeek’s research papers and are now refined for production use.
Key Algorithmic Innovations
DeepSeek’s efficiency-first approach relies on several groundbreaking techniques:
1. FP8 Training for Memory Efficiency
Unlike most large-scale models that use 16-bit or 32-bit floating-point formats, DeepSeek V3 is trained natively in 8-bit floating-point (FP8). This significantly reduces memory requirements without compromising performance. Given the restrictions on high-end GPUs and export controls to China, this optimization is particularly crucial.

2. FP8 Accumulation Fix
A challenge with FP8 training is potential numerical instability. To counter this, DeepSeek implements a method that periodically merges calculations back into a higher-precision FP32 accumulator, ensuring stable and accurate computations while maintaining efficiency.
3. Mixture of Experts (MoE) Architecture
DeepSeek V3 adopts a Mixture of Experts (MoE) design:
- While the model has 671 billion parameters, only 37 billion are activated per token prediction.
- In contrast, models like Llama 3 (405 billion parameters) activate their entire parameter set per forward pass, leading to higher compute costs.
- This selective activation approach drastically reduces computational expense while retaining model effectiveness.
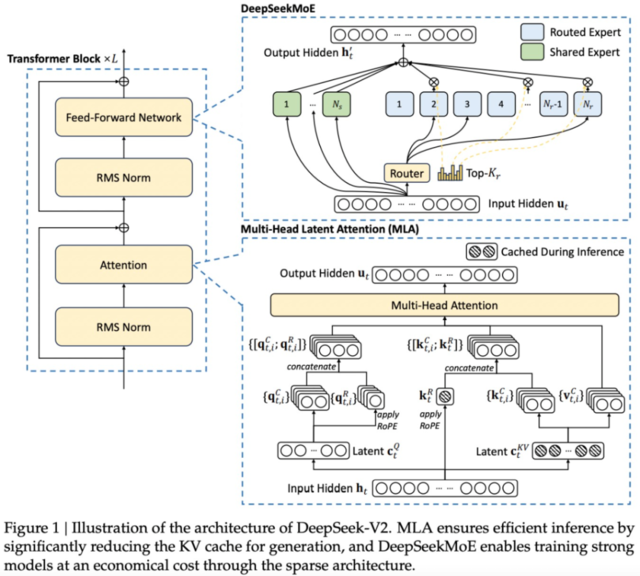
4. Multi-Head Latent Attention (MLA)
A key efficiency bottleneck in large models is KV cache memory usage. DeepSeek V3 employs Multi-Head Latent Attention (MLA) to address this:
- Key and value matrices are compressed into a latent space and only reconstructed when needed.
- In their earlier V2 model, this led to a 93.3% reduction in KV cache size and a 5.76x improvement in throughput.
- The efficiency gains in V3 further improve inference speed, making deployment more scalable.
5. Multi-Token Prediction (MTP)
Traditional language models predict one token at a time, but DeepSeek V3 employs Multi-Token Prediction (MTP):
- The model predicts multiple future tokens per step, increasing training signal density.
- This leads to smoother, more coherent outputs and enables faster inference.
- MTP modules can also be adapted for speculative decoding, speeding up response times significantly.
Reasoning Model Training: The R1 Advantage
DeepSeek R1 is tailored for complex, step-by-step problem-solving, setting it apart from general-purpose LLMs. Key innovations include:
1. Reinforcement Learning (RL) for Logical Thinking
- DeepSeek trains R1 using reinforcement learning (RL) on problems with verifiable answers (e.g., math and coding tasks).
- Unlike traditional fine-tuning, this method helps the model learn reasoning strategies autonomously, rather than just mimicking examples.
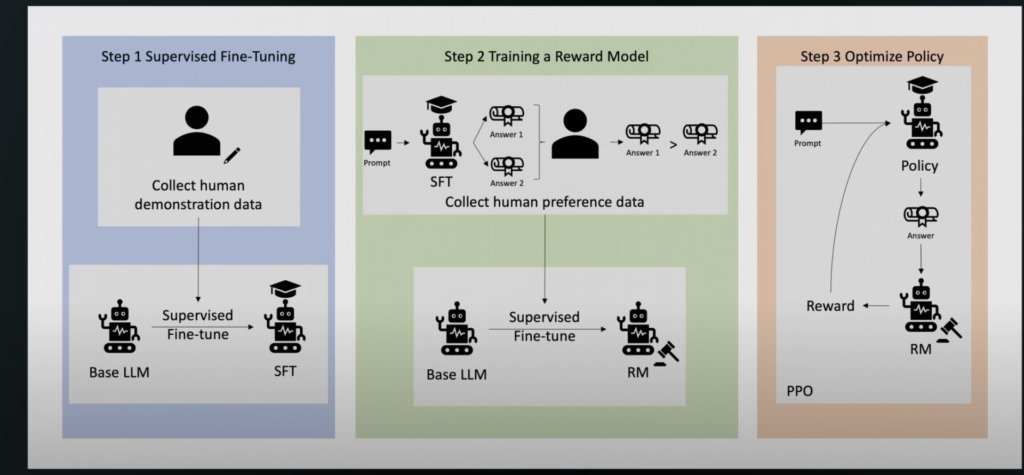
2. Simple Rule-Based Evaluation
- Instead of complex AI-based reward models, DeepSeek evaluates model responses with simple rule-based grading systems.
- This reduces training overhead while maintaining high-quality outputs.
3. Group Relative Policy Optimization (GRPO)
- GRPO is a novel RL technique that updates the model based on relative rankings of outputs, leading to the emergence of structured reasoning skills like extended Chain of Thought (CoT).
Addressing Early Issues
Initially, R1 suffered from poor readability and inconsistent language switching between English and Chinese. To resolve this, DeepSeek implemented a cold-start fine-tuning phase, using structured reasoning examples before RL training.
Performance and Accessibility
DeepSeek R1 demonstrates strong performance, rivaling OpenAI’s models on math and coding benchmarks. Beyond accuracy, its cost-effectiveness and accessibility set it apart:
- Open Source: R1 is freely available on DeepSeek’s website and app.
- Customizable: The model can be downloaded, run locally, and fine-tuned for specialized use cases.
DeepSeek’s emphasis on algorithmic efficiency makes R1 a compelling option for researchers and developers with limited access to high-end compute resources.
Replicability: Can Others Follow Suit?
One of the most intriguing claims about DeepSeek V3 is its low training cost—just $5.5 million for the final training run. However, this figure excludes R&D and hardware costs, which likely amount to hundreds of millions.
Despite this, the underlying techniques are replicable:
- A UC Berkeley lab successfully applied similar optimizations to a smaller-scale model, achieving advanced reasoning capabilities for just $30 in compute costs.
- This suggests that efficiency-focused AI development can democratize access to cutting-edge capabilities.
Conclusion
DeepSeek R1 is a testament to the untapped potential of efficiency-driven AI innovation. By leveraging:
- FP8 training for memory savings
- Mixture of Experts (MoE) for selective computation
- Multi-Head Latent Attention (MLA) for KV cache reduction
- Reinforcement learning (RL) and GRPO for structured reasoning
DeepSeek has proven that state-of-the-art performance can be achieved at a fraction of the typical cost.
As AI development moves forward, models like R1 will likely shape the future of scalable and accessible reasoning-based AI. Whether through open-source contributions or enterprise applications, the DeepSeek approach is poised to drive the next wave of AI advancements.