Natural Language Processing (NLP) has revolutionized the way machines understand human language. But before models can learn from text, they need a way to break it down into smaller, understandable units. This is where tokenization comes in — a critical preprocessing step that transforms raw text into a sequence of meaningful components, or tokens.
🧠 What is Tokenization?
Tokenization is the process of splitting text into smaller units called tokens. These tokens can be as large as words, or as small as characters or subwords.
Example:
Input: "ChatGPT is powerful!"
Word-level tokens: ["ChatGPT", "is", "powerful", "!"]
Character-level tokens: ["C", "h", "a", "t", "G", "P", "T", " ", "i", "s", " ", "p", "o", "w", "e", "r", "f", "u", "l", "!"]
🏛 Classical vs Modern Tokenization
🔹 Classical Tokenization (Rule-based)
Older NLP systems relied on simple rule-based tokenizers, often splitting on whitespace and punctuation.
Pros:
- Easy to implement
- Human-readable tokens
Cons:
- Doesn’t handle compound words, typos, or unknown words well
- Language-dependent
Popular classical tools:
- NLTK’s
word_tokenize - spaCy tokenizer
from nltk.tokenize import word_tokenize
word_tokenize("Let's tokenize this!")
# Output: ["Let", "'s", "tokenize", "this", "!"]
🔹 Modern Tokenization (Subword-based)
In modern Transformer-based models, tokenization is more sophisticated:
- Byte-Pair Encoding (BPE) – GPT-2/3
- WordPiece – BERT
- Unigram Language Model – SentencePiece / T5
These methods break words into subword units to address Out-Of-Vocabulary (OOV) issues and reduce the vocabulary size.
Example (BPE):
Input: "unhappiness"
Tokens: ["un", "happiness"] or ["un", "happi", "ness"]
Tokenization using Hugging Face Transformer.js libraray
You need these two files to load the tokenizer using the Hugging Face tokenizer library.
tokenizer_config.json
tokenizer.jsonUsing this code, you can load these files, and count the tokens in a sentence, and also get the token ids
await AutoTokenizer.from_pretrained(pretrained_model_name_or_path)the tokenizer can be initialized using either:
- A model ID string from the Hugging Face Hub:
These are publicly hosted models like:"bert-base-uncased""gpt2""facebook/bart-large-cnn""dbmdz/bert-base-german-cased"(note the namespaced format:user_or_org/model_name)
- A local directory path:
If you’ve downloaded or fine-tuned a tokenizer and saved it locally, you can point to that directory:
tokenizer = AutoTokenizer.from_pretrained("./my_model_directory/")This flexibility allows you to either use official models from Hugging Face or load your custom/pretrained tokenizers from disk.
To get the tokens, you can call encode on the tokenizer instance
const tokens = tokenizer.encode(text);If the model uses BPE internally, encode function invokes that.
Internally, BPE uses a cache, now, this uses an LRU cache. Earlier it was a simple hashmap, which resulted in a memory leak kind of scenario, if you called the encode function with different input, it would cache all the results.
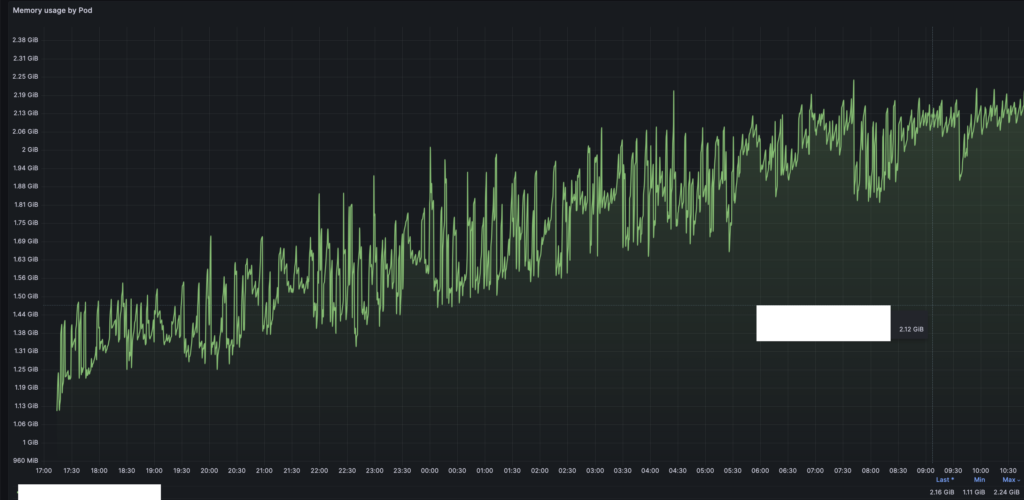
This is how the memory kept on increasing when I used this. This issue is fixed now.
https://github.com/huggingface/transformers.js/issues/1282
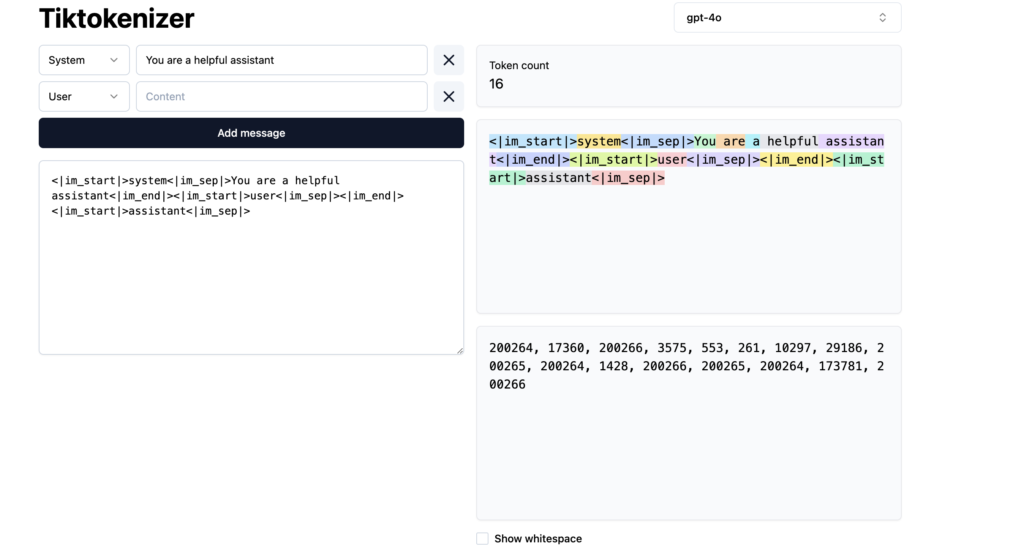
To count tokens or to see how different models tokenized text, you can check this app