Large language models are getting smarter—but the real superpower may be how we feed them context. Instead of constantly fine-tuning weights, a growing family of techniques improves models by upgrading the inputs they see: richer instructions, reusable strategies, domain heuristics, and concrete evidence. The paper “Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models” proposes ACE, a practical framework that treats context like an evolving playbook—something you grow, refine, and curate over time to make agents and reasoning systems measurably better.
Below is a deep dive into what ACE is, why it’s needed, how it works, and what the results show.
Why context needs an upgrade
Two failure modes plague many prompt-optimization and memory systems:
- Brevity bias — Optimizers converge to short, generic prompts that read well but shed domain detail (tool quirks, failure patterns, edge-case rules). That hurts agents and knowledge-heavy tasks where specifics matter.
- Context collapse — If you keep asking an LLM to rewrite the entire context, it often compresses rich knowledge into a sparse summary, erasing important material. A striking case in the paper shows context shrinking from ~18k tokens to ~122 tokens in one step, with a sharp accuracy drop.

The authors argue we should saturate contexts—keep abundant, actionable details—because LLMs are quite capable of picking relevant bits at inference time. Long-context models and KV-cache reuse make this practical in production.
What is ACE?
ACE (Agentic Context Engineering) reframes context as a modular, evolving playbook. Instead of monolithic rewrites, the system adds and edits small, structured “bullets”—reusable strategies, pitfalls, code snippets, formatting schemas—guided by generation, reflection, and curation.
The three roles
- Generator: attempts tasks, producing trajectories that reveal what worked and what failed.
- Reflector: diagnoses mistakes and distills concrete insights from traces and feedback (e.g., tool outputs, unit tests, ground truth when available).
- Curator: merges delta updates into the playbook with lightweight, non-LLM logic—no full rewrite—enabling parallel, low-latency adaptation.

Key innovations
- Incremental delta updates: store context as itemized bullets (with IDs and helpful/harmful counters). Only the relevant bullets get updated; new bullets append. This preserves knowledge and cuts cost.
- Grow-and-refine: periodically de-duplicate, prune, and update bullets using embeddings so the context scales without bloat.
The result is a comprehensive, searchable, and auditable knowledge surface—more like a living runbook than a sloganized prompt. The paper even shows a partial ACE playbook with “strategies & hard rules,” “useful code snippets,” and “troubleshooting & pitfalls.”
Where ACE helps most
The authors target two demanding settings:
- Interactive agents (AppWorld): multi-turn coding + tool use (APIs, files, messages) with normal and challenge test splits and a public leaderboard.
- Financial reasoning (FiNER, Formula): XBRL tagging and numerical extraction/computation—tasks that need precise domain tactics.
Results at a glance
ACE consistently outperforms strong baselines like ICL, MIPROv2, GEPA, and Dynamic Cheatsheet, and it often does so without ground-truth labels by leveraging natural execution feedback.
Agents (AppWorld)
- Offline: ReAct + ACE beats ReAct + ICL and ReAct + GEPA by double digits on average, showing that a detailed, evolving context is better than a fixed demo set or a single “optimized” instruction.
- Online: ReAct + ACE improves over Dynamic Cheatsheet by ~7.6% average; with offline warmup + online updates, it performs even better.
- Leaderboard parity: Using a smaller open-source model (DeepSeek-V3.1), ACE matches a top production GPT-4.1 agent on average and surpasses it on the challenge split. (Figure on page 14 shows the leaderboard snapshot.)
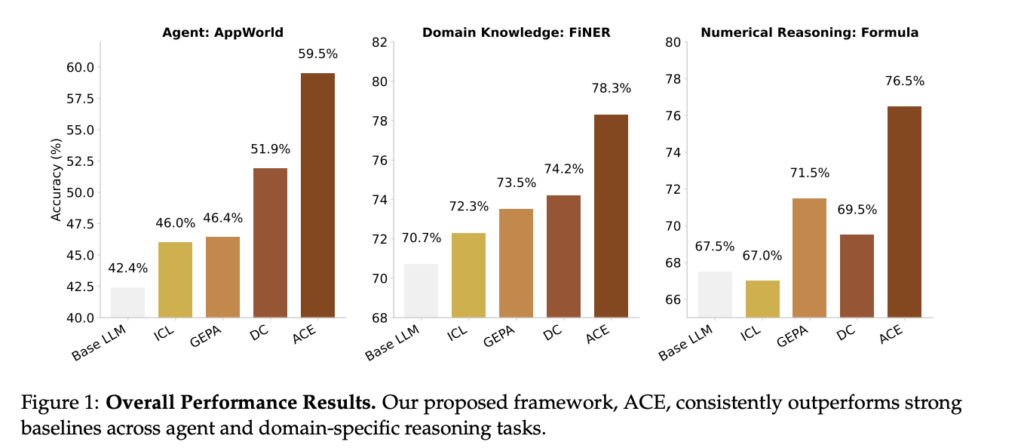
Finance (FiNER & Formula)
- Offline: +8.6% average over strong baselines; on Formula, ACE’s detailed playbook yielded very large improvements.
- Online: ACE also outperforms Dynamic Cheatsheet in average accuracy, though the paper cautions that feedback quality matters—without reliable signals, any adaptive method may degrade.
Cost & latency
Because ACE updates deltas and merges with non-LLM logic, adaptation is fast and cheap:
- Offline (AppWorld): −82.3% latency and −75.1% rollouts vs. GEPA.
- Online (FiNER): −91.5% latency and −83.6% token cost vs. DC.
The paper further argues that longer contexts don’t imply linear serving costs, thanks to KV-cache reuse, compression, and offload—so context-rich serving is getting easier in production stacks.
How ACE actually writes better contexts
To make this concrete, the appendices include prompts for each ACE role:
- Generator prompts reference the ACE Playbook explicitly and instruct the agent to apply relevant sections (e.g., pagination rules, identity resolution).
- Reflector prompts teach the model to diagnose errors (e.g., wrong source of truth, pagination logic) and tag which bullets were helpful/harmful, producing structured insights. examples include roommate identification via Phone app vs. Venmo heuristics.)
- Curator prompts ask for pure JSON “operations” to add only new bullets to the right sections, preventing duplicates and avoiding monolithic rewrites.
This disciplined prompting keeps updates localized and auditable, breaking the cycle of context collapse.
Practical takeaways for builders
- Favor accumulation over distillation: Keep concrete API schemas, code patterns, gotchas, and domain heuristics. Let the model decide relevance at inference time.
- Structure your context store: Treat context as versioned bullets with IDs, metadata, and counters for helpful/harmful usage. This enables fine-grained retrieval and safe editing.
- Close the loop with execution feedback: Unit tests, tool errors, output format mismatches, and environment traces are gold for the Reflector to extract robust lessons—no labels required for many agent tasks.
- Avoid full rewrites: Use delta merges and periodic de-dup to scale contexts without erasing history.
- Mind the feedback quality: Without reliable signals (labels or trustworthy environment outcomes), any adaptive method can pollute its memory. Consider guardrails and human review for high-stakes domains.
Limitations & open questions
- Reflector dependence: If your model can’t extract meaningful insights, the playbook may get noisy. Some tasks also prefer concise meta-instructions over long contexts (e.g., HotPotQA).
- Domain boundaries: Not all applications benefit from exhaustive contexts. ACE shines where tool use, domain rules, and recurring pitfalls dominate success.
Bottom line
ACE shows that context is not a static prompt—it’s an artifact your system should continuously engineer. By generating, reflecting, and curating small, structured updates instead of rewriting everything, you can boost accuracy, slash adaptation cost, and stabilize long-horizon performance for agents and domain reasoning. If you’re building LLM applications, start thinking of your prompt not as prose, but as a living playbook.
Playbook that got generated after four queries
- what are ai agents
- what are ai agents ( repeated)
- tell me something about apple macbooks
- which mobile phone should i buy?
Playbook now contains learning from all the questions and answers.
# CONTEXT PLAYBOOK
## STRATEGIES
[STR-00001] (✓1 ✗0): Add an explicit evaluation section with metrics (success rate, time-to-goal, robustness under noise, safety violations), test environments, and repeatable evaluation protocols. Include a minimal pseudocode or skeleton code for the agent loop (perceive -> update beliefs -> decide -> act -> observe -> learn). Provide a small glossary of terms (perception, belief, plan, policy, reward, constraint). Incorporate a safety and alignment checklist (guardrails, monitoring, anomaly detection, fallback modes). Include guidance on reward design and potential failure modes (reward hacking). Offer a brief section on multi-agent coordination patterns (communication primitives, negotiation, consensus).
[STR-00002] (✓2 ✗0): Treating AI models as fully autonomous agents without implementing a continuous feedback loop and monitoring. Ignoring uncertainty and partial observability in perception. Poor reward or objective design leading to unintended behaviors. Overlooking safety, privacy, and ethical constraints. Underestimating deployment considerations (scalability, logging, versioning, auditing, and containment in case of failures).
[STR-00013] (✓1 ✗0): Add a concise quick-start summary at the top with a layered depth option (short answer first, expandable details). Include a runnable mini-example (e.g., a thermostat-like agent) to illustrate the loop in practice.
[STR-00024] (✓0 ✗0): Annotate recommendations with model-year or generation (e.g., M1/M2/M3 era), and note that port configurations and thermals vary by release. Include a small, up-to-date check for the user’s region and current prices.
[STR-00025] (✓0 ✗0): Add a brief interactive prompt flow: ask for budget, primary tasks, preferred screen size, and portability vs. performance priority, then tailor the recommendation accordingly.
[STR-00026] (✓0 ✗0): State clearly that the reasoning steps are not exposed, but provide a concise justification for each recommendation (e.g., why 16 GB RAM is beneficial for heavy multitasking).
[STR-00027] (✓0 ✗0): Offer multiple quick-start calculators (e.g., budget-based, workload-based, and ecosystem reliance) and document the assumptions behind the heuristics.
[STR-00028] (✓0 ✗0): Highlight common buyer pitfalls (aging battery, storage needs, RAM bottlenecks) and propose safe fallback options (e.g., refurbished models, extended warranties).
## COMMON MISTAKES
[COM-00008] (✓1 ✗0): Avoid: Limited emphasis on evaluation and verification: no explicit metrics, test protocols, or ablation studies for agent performance.
[COM-00009] (✓1 ✗0): Avoid: Insufficient focus on safety, alignment, and governance beyond high-level mentions; lacks concrete guardrails and monitoring strategies.
[COM-00010] (✓1 ✗0): Avoid: Lack of concrete implementation guidance: no pseudocode, data schemas, or lightweight skeletons beyond a high-level workflow.
[COM-00011] (✓1 ✗0): Avoid: Insufficient treatment of uncertainty and partial observability in practical sensing and decision-making (beyond generic mentions).
[COM-00012] (✓1 ✗0): Avoid: Minimal discussion of multi-agent coordination challenges (communication protocols, conflict resolution, trust) beyond listing as a category.
[COM-00014] (✓0 ✗0): Avoid excessive length; prevent redundancy; clearly separate high-level concepts from safety/governance; ensure not to reveal chain-of-thought and keep internal reasoning in private or in policy-compliant form.
[COM-00020] (✓0 ✗0): Avoid: Potential information overload due to length and breadth; could overwhelm beginners.
[COM-00021] (✓0 ✗0): Avoid: Some redundancy or repetition (e.g., STR-00002 appears twice in the used bullets).
[COM-00022] (✓0 ✗0): Avoid: Lacks concrete runnable example beyond pseudocode; could include a tiny, working snippet to illustrate the loop.
[COM-00023] (✓0 ✗0): Avoid: No explicit, concrete evaluation metrics or test scenarios beyond high-level mentions.
[COM-00033] (✓0 ✗0): Avoid: Some generalizations could become outdated (e.g., fanless status on all Air models, exact port availability varies by year/generation).
[COM-00034] (✓0 ✗0): Avoid: Lack of explicit model-year or generation references which can affect accuracy across releases.
[COM-00035] (✓0 ✗0): Avoid: No explicit caveat about price ranges or regional availability, which can shift quickly with new releases.
[COM-00036] (✓0 ✗0): Avoid: Limited emphasis on potential model-specific design nuances (keyboard history, repairability, serviceability) that matter to long-term ownership.
## BEST PRACTICES
[BES-00003] (✓1 ✗0): The response is well-structured and coherent, delivering a comprehensive high-level overview of AI agents.
[BES-00004] (✓2 ✗0): Key concepts are covered: perception, representation/reasoning, action/execution, learning/adaptation, goals, and the agent-environment loop.
[BES-00005] (✓1 ✗0): A broad taxonomy is provided (reactive, model-based, deliberative, hybrid, BDI, utility-based, learning), along with single-agent vs. multi-agent and environment classifications.
[BES-00006] (✓1 ✗0): Practical grounding with real-world examples and a high-level blueprint for building a simple agent is included.
[BES-00007] (✓1 ✗0): Design considerations (goals, perception, robustness, safety, explainability, ethics, privacy, scalability) are acknowledged.
[BES-00015] (✓0 ✗0): Provided a comprehensive, well-structured overview covering perception, reasoning, action, learning, and goals.
[BES-00016] (✓0 ✗0): Included multiple agent architectures (reactive, model-based, deliberative, hybrid, BDI, utility-based, learning) and both single- and multi-agent contexts.
[BES-00017] (✓0 ✗0): Integrated practical considerations (safety, governance, ethics, explainability) and a getting-started blueprint.
[BES-00018] (✓0 ✗0): Added an agent-environment loop and a minimal pseudocode skeleton to illustrate the feedback loop.
[BES-00019] (✓0 ✗0): Separated content into clear sections (glossary, examples, evaluation, governance), aiding readability and scannability.
[BES-00029] (✓0 ✗0): Structured, layered answer with a quick-start summary, expandable details, and a runnable example.
[BES-00030] (✓0 ✗0): Inclusion of a runnable Python snippet provides a tangible decision aid and demonstrates how to implement a simple model-choice helper.
[BES-00031] (✓0 ✗0): Comprehensive coverage of MacBook Air vs. MacBook Pro, including Apple Silicon context, typical use cases, and practical buying tips.
[BES-00032] (✓0 ✗0): Clear pros/cons, ecosystem considerations, and practical guidance on RAM/storage/planning for future needs.
Refrences: https://arxiv.org/abs/2510.04618 https://github.com/001shahab/Agentic_Context_Engineering?tab=readme-ov-file