Introduction
Embeddings are numerical representations of concepts converted to number sequences, which make it easy for computers to understand the relationships between those concepts.
Whether it’s natural language processing, computer vision, recommender systems, or other applications, embeddings play a crucial role in enhancing model performance and scalability.
Text embeddings measure the relatedness of text strings. Embeddings are commonly used for:
- Search (where results are ranked by relevance to a query string)
- Clustering (where text strings are grouped by similarity)
- Recommendations (where items with related text strings are recommended)
- Anomaly detection (where outliers with little relatedness are identified)
- Diversity measurement (where similarity distributions are analyzed)
- Classification (where text strings are classified by their most similar label)
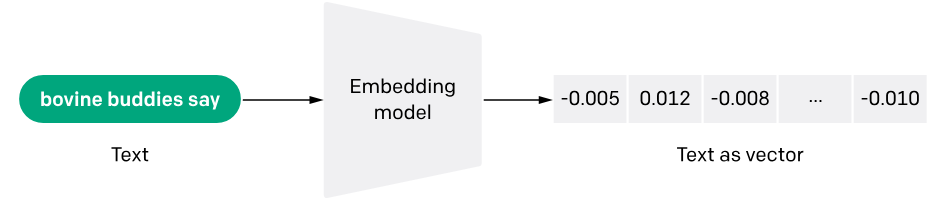
There are a lot of models that we can use, some are free and some are paid and available via API. In this blog, we will see one example of both.
First, let’s check the Open AI Embeddings.
Open AI Embeddings
curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"input": "Your text string goes here",
"model": "text-embedding-3-small"
}'{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
... (omitted for spacing)
-4.547132266452536e-05,
-0.024047505110502243
],
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}the length of the embedding vector will be 1536 for text-embedding-3-small or 3072 for text-embedding-3-large.
Sbert Embeddings
SentenceTransformers is a Python framework for state-of-the-art sentence, text and image embeddings.
Install the sentence-transformers with pip:
pip install -U sentence-transformersfrom sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
# Our sentences we like to encode
sentences = [
"This framework generates embeddings for each input sentence",
"Sentences are passed as a list of strings.",
"The quick brown fox jumps over the lazy dog.",
]
# Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
# Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")You can wrap this code in Django server code, and serve as an API.
Several prominent embedding models exist, comprising:
- Word2Vec: Engineered by Google, this model leverages neural networks to glean word embeddings from extensive textual datasets.
- GloVe: Forged by Stanford, this acronym signifies “Global Vectors for Word Representation,” employing a fusion of matrix factorization and co-occurrence statistics to derive word embeddings.
- FastText: Crafted by Facebook, this model resembles Word2Vec but also integrates subword information (e.g., character n-grams) to formulate word embeddings.
- ELMO (Embeddings from Language Models): Engineered by AllenNLP, ELMO employs a deep bidirectional language model to craft embeddings tailored for specific tasks through fine-tuning.
To know more about Sbert check this link : SentenceTransformers Documentation — Sentence-Transformers documentation (sbert.net)
To know more about OpenAI Embeddings check this link : Embeddings – OpenAI API
Lets see the clustering in action with the following code sample, using Sbert
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from sentence_transformers import SentenceTransformer
# Initialize the Sentence Transformer model
model = SentenceTransformer("all-MiniLM-L6-v2")
#t-SNE stands for t-Distributed Stochastic Neighbor Embedding.
# It's a dimensionality reduction technique commonly used for visualizing high-dimensional data in a lower-dimensional space,
# typically 2D or 3D. t-SNE is particularly effective at preserving the local structure of the data,
# making it useful for visualizing clusters or patterns in complex datasets.
# Our sentences to encode
sentences = [
"cat", "dog", "elephant", "lion", "tiger", # Animals
"swim", "dive", "surf", "boat", "ocean", # Water-related
"run", "jump", "athlete", "sports", "fitness", # Athlete-related
"code", "programming", "developer", "software", "computer", # Coding-related
"fish", "shark", "whale", "dolphin", "octopus", # Marine animals
"sprint", "marathon", "exercise", "gym", "race", # Exercise-related
"data", "algorithm", "python", "java", "javascript", # Programming languages
"bird", "eagle", "falcon", "penguin", "parrot", # Birds
"swimmer", "diver", "surfer", "sailor", "fisherman", # Water-related roles
"soccer", "basketball", "football", "tennis", "volleyball", # Sports
"debug", "compile", "function", "variable", "loop", # Coding terms
"horse", "zebra", "giraffe", "cheetah", "kangaroo", # Safari animals
"drown", "float", "wave", "current", "splash", # Water actions
"runner", "cyclist", "swimmer", "jumper", "climber", # Athlete roles
"database", "API", "framework", "library", "interface", # Software terms
"frog", "turtle", "crocodile", "alligator", "lizard", # Reptiles
"scuba", "surfboard", "paddle", "kayak", "snorkel", # Water equipment
"gymnast", "weightlifter", "skater", "surfer", "dancer" # Athletic roles
]
# Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
# Perform dimensionality reduction for visualization using t-SNE
tsne = TSNE(n_components=2, perplexity=5, random_state=42) # Adjust perplexity here
embeddings_2d = tsne.fit_transform(embeddings)
# Visualize embeddings in 2D
plt.figure(figsize=(10, 6))
plt.title("t-SNE Visualization of Embeddings (2D)")
plt.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1])
for i, sentence in enumerate(sentences):
plt.annotate(sentence, (embeddings_2d[i, 0], embeddings_2d[i, 1]))
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.grid(True)
plt.show()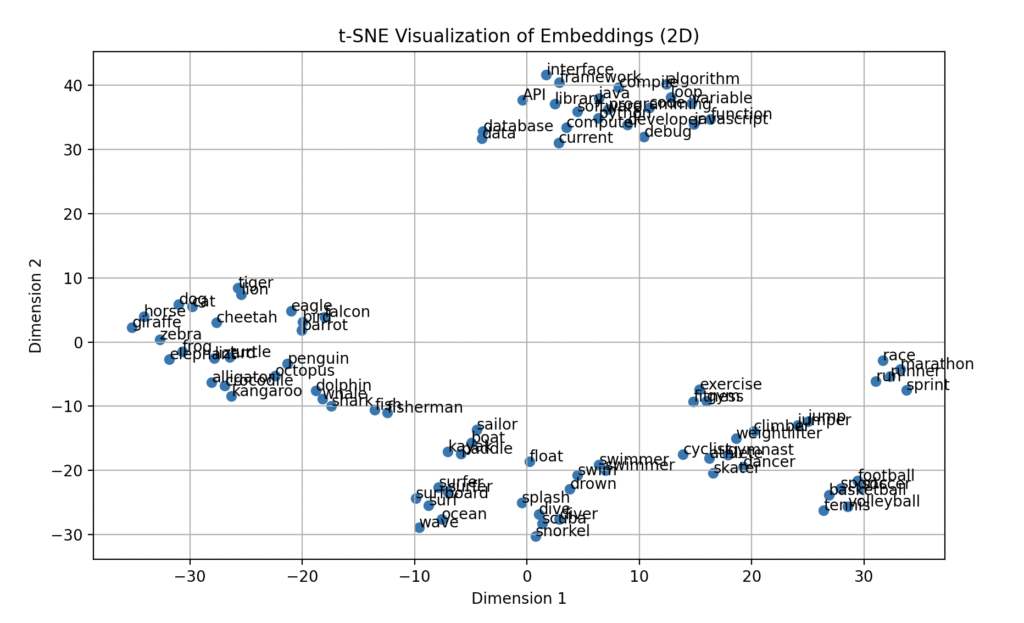
Vector databases serve as robust repositories for storing embeddings. By leveraging specialized data structures and indexing techniques, vector databases facilitate seamless integration with applications requiring semantic understanding and context-aware processing.
These databases are optimized for efficient storage and retrieval of high-dimensional vectors, enabling fast querying and similarity searches.
We will learn about Vector databases in another blog.
Your post is a fantastic combination of thorough research and engaging writing. Well done!