Introduction
In today’s data-driven landscape, businesses require robust tools to efficiently process, transform, and analyze data for deriving meaningful insights. Google Dataflow is a solution, offering a powerful, fully managed service on the Google Cloud Platform (GCP) that simplifies the complexities of building data pipelines.
Key Features of Google Dataflow
Google Dataflow boasts several key features that make it indispensable for modern data processing needs:
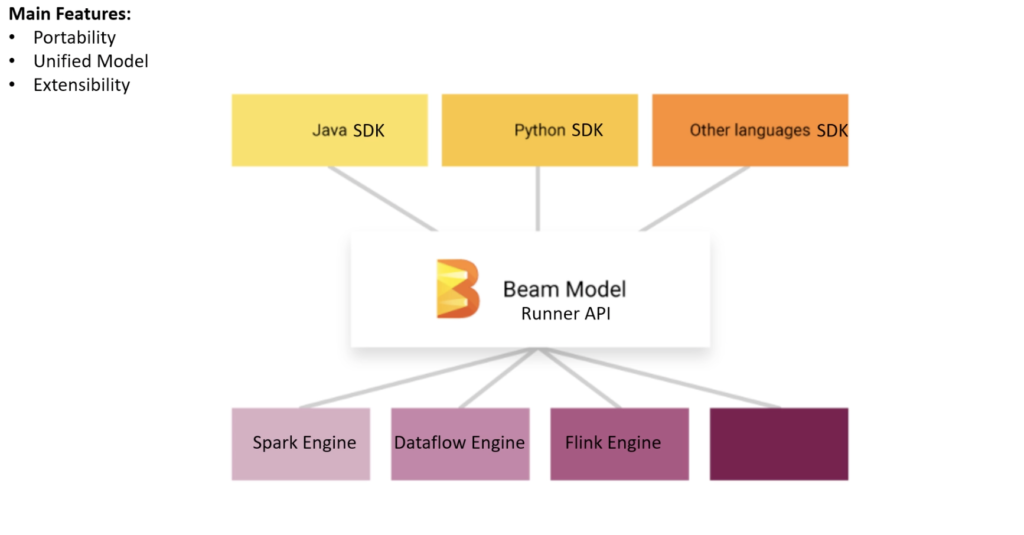
- Unified Model for Batch and Stream Processing: Dataflow leverages the Apache Beam SDK, providing a unified approach to code both batch and streaming data pipelines. This eliminates the need for maintaining separate systems and skillsets for different processing types.
- Serverless and Auto-scaling: As a fully managed service, Dataflow handles infrastructure management seamlessly, automatically scaling resources based on workload to ensure cost-efficiency.
- Focus on Logic, not Infrastructure: Dataflow allows users to concentrate on the core logic of data transformation while handling distributed processing, fault tolerance, and resource provisioning intricacies.
- Rich Integration with GCP: Deep integration with other GCP services such as Cloud Pub/Sub, BigQuery, and Cloud Storage enables users to develop end-to-end data engineering solutions within the Google Cloud ecosystem.
Real-Time Analytics with Pub/Sub to BigQuery Pipelines
One of the most compelling use cases of Google Dataflow is its capability to build real-time data ingestion and analysis pipelines using Cloud Pub/Sub and BigQuery. Below, are outlined the steps involved in constructing such pipelines.
Data Ingestion with Cloud Pub/Sub:
- Cloud Pub/Sub serves as a highly scalable messaging service allowing seamless decoupling of data producers and consumers.
- Applications publish messages to Pub/Sub topics, and interested subscribers consume them asynchronously.
Real-Time Processing with Dataflow
- A Dataflow pipeline subscribes to a Pub/Sub topic, processing incoming messages in real-time.
- Key processing steps include data cleaning and validation, transformation and enrichment, as well as windowing and aggregation for calculating metrics over specified time windows.
Loading Data into BigQuery
- BigQuery, a serverless data warehouse, facilitates efficient storage and querying of processed data.
- Dataflow seamlessly writes processed data into BigQuery tables, supporting both streaming and batch modes.
Analytics and Visualization
- BigQuery’s SQL-like interface empowers users to perform complex queries for in-depth analysis.
- Tools like Google Data Studio or Looker can be connected to BigQuery to create interactive dashboards and reports for visualization.
Building a Pub/Sub to BigQuery Pipeline
Google Cloud provides pre-built Dataflow templates that streamline the process of creating such pipelines. Follow these steps to create a pipeline:
- Access the Dataflow console in GCP.
- Select the “Pub/Sub Subscription to BigQuery” template.
- Configure parameters including Pub/Sub input subscription, BigQuery output table, and temporary storage location.
- Launch the job to initiate the pipeline execution.
Writing custom code with Apache Bean SDK for batch processing
# Import necessary libraries and modules
import apache_beam as beam
import os
from apache_beam.options.pipeline_options import PipelineOptions
# Define pipeline options
pipeline_options = {
'project': 'dataflow-course-319517' ,
'runner': 'DataflowRunner',
'region': 'southamerica-east1',
'staging_location': 'gs://dataflow-course/temp',
'temp_location': 'gs://dataflow-course/temp',
'template_location': 'gs://dataflow-course/template/batch_job_df_bq_flights' ,
'save_main_session': True
}
# Create pipeline with defined options
pipeline_options = PipelineOptions.from_dictionary(pipeline_options)
p1 = beam.Pipeline(options=pipeline_options)
# Set service account credentials
serviceAccount = r"C:\Users\cassi\Google Drive\GCP\Dataflow Course\Meu_Curso_EN\dataflow-course-319517-4f98a2ce48a7.json"
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]= serviceAccount
# Define DoFn classes for data processing
class split_lines(beam.DoFn):
"""Splits each line of input record."""
def process(self, record):
return [record.split(',')]
class Filter(beam.DoFn):
"""Filters records based on a condition."""
def process(self, record):
if int(record[8]) > 0:
return [record]
# Define functions for data transformation
def dict_level1(record):
"""Creates level-1 dictionary."""
dict_ = {}
dict_['airport'] = record[0]
dict_['list'] = record[1]
return(dict_)
def unnest_dict(record):
"""Unnests nested dictionaries."""
def expand(key, value):
if isinstance(value, dict):
return [(key + '_' + k, v) for k, v in unnest_dict(value).items()]
else:
return [(key, value)]
items = [item for k, v in record.items() for item in expand(k, v)]
return dict(items)
def dict_level0(record):
"""Creates level-0 dictionary."""
dict_ = {}
dict_['airport'] = record['airport']
dict_['list_Delayed_num'] = record['list_Delayed_num'][0]
dict_['list_Delayed_time'] = record['list_Delayed_time'][0]
return(dict_)
# Define table schema for BigQuery
table_schema = 'airport:STRING, list_Delayed_num:INTEGER, list_Delayed_time:INTEGER'
table = 'dataflow-course-319517:flights_dataflow.flights_aggr'
# Define pipeline steps for Delayed_time and Delayed_num
Delayed_time = (
p1
| "Import Data time" >> beam.io.ReadFromText(r"gs://dataflow-course/input/flights_sample.csv", skip_header_lines=1)
| "Split by comma time" >> beam.ParDo(split_lines())
| "Filter Delays time" >> beam.ParDo(Filter())
| "Create a key-value time" >> beam.Map(lambda record: (record[4], int(record[8])))
| "Sum by key time" >> beam.CombinePerKey(sum)
)
Delayed_num = (
p1
| "Import Data" >> beam.io.ReadFromText(r"gs://dataflow-course/input/flights_sample.csv", skip_header_lines=1)
| "Split by comma" >> beam.ParDo(split_lines())
| "Filter Delays" >> beam.ParDo(Filter())
| "Create a key-value" >> beam.Map(lambda record: (record[4], int(record[8])))
| "Count by key" >> beam.combiners.Count.PerKey()
)
# Define pipeline steps for creating the Delay_table
Delay_table = (
{'Delayed_num': Delayed_num, 'Delayed_time': Delayed_time}
| "Group By" >> beam.CoGroupByKey()
| "Unnest 1" >> beam.Map(lambda record: dict_level1(record))
| "Unnest 2" >> beam.Map(lambda record: unnest_dict(record))
| "Unnest 3" >> beam.Map(lambda record: dict_level0(record))
| "Write to BQ" >> beam.io.WriteToBigQuery(
table,
schema=table_schema,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND,
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
custom_gcs_temp_location='gs://dataflow-course/temp'
)
)
# Execute the pipeline
p1.run()
Code references: https://www.udemy.com/course/data-engineering-with-google-dataflow-and-apache-beam/

Conculsion
Google Dataflow emerges as a versatile platform for stream and batch data processing, offering seamless integration with other GCP services and enabling users to focus on data logic rather than infrastructure management.