Introduction
TF-IDF (Term Frequency-Inverse Document Frequency) is a statistical measure used to evaluate the importance of a word in a document relative to a collection of documents (corpus). It combines two metrics: Term Frequency (TF) and Inverse Document Frequency (IDF). The TF-IDF value increases proportionally with the number of times a word appears in the document and is offset by the frequency of the word in the corpus.
Components of TF-IDF
Term Frequency (TF): Measures how frequently a term appears in a document. It’s calculated as:

Inverse Document Frequency (IDF): Measures how important a term is. While computing TF, all terms are considered equally important. IDF reduces the weight of terms that appear very frequently in the document set and increases the weight of terms that appear rarely. It’s calculated as:

TF-IDF: The product of TF and IDF for a term. It’s calculated as:

Example Calculation
Consider a small corpus of three documents:
- Document 1 (D1): “the cat sat on the mat”
- Document 2 (D2): “the cat sat”
- Document 3 (D3): “the cat”
Let’s calculate the TF-IDF for the term “cat” in each document.
- Calculate Term Frequency (TF)
- D1: TF(cat, D1) = 1/6 (since “cat” appears once and there are 6 words in D1)
- D2: TF(cat, D2) = 1/3
- D3: TF(cat, D3) = 1/2
- Calculate Inverse Document Frequency (IDF) : The term “cat” appears in all three documents, so:

Since the IDF is zero, it means the term “cat” is not useful in distinguishing between documents in this corpus.
When using sklearn‘s TfidfVectorizer, the IDF calculation includes smoothing to prevent division by zero. The formula used by sklearn is:

Code to calculate TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# Sample corpus
corpus = [
"the cat sat on the mat",
"the cat sat",
"the cat"
]
# Initialize the vectorizer
vectorizer = TfidfVectorizer()
# Fit and transform the corpus
X = vectorizer.fit_transform(corpus)
# Convert the result to a dense matrix and print it
df = pd.DataFrame(X.toarray(), columns=vectorizer.get_feature_names_out())
print(df)
sklearn TfidfVectorizer normalizes the vectors by default. This normalization affects the final TF-IDF scores, ensuring they are unit vectors.
The sklearn TfidfVectorizer uses L2 normalization by default. The L2 norm of a vector
![$$ v = \left[ v_1, v_2, \dots, v_n \right] $$](https://learncodecamp.net/wp-content/ql-cache/quicklatex.com-821f25d1aef1c3e3e4380d07e250f11a_l3.png "Rendered by QuickLaTeX.com")
is defined as:

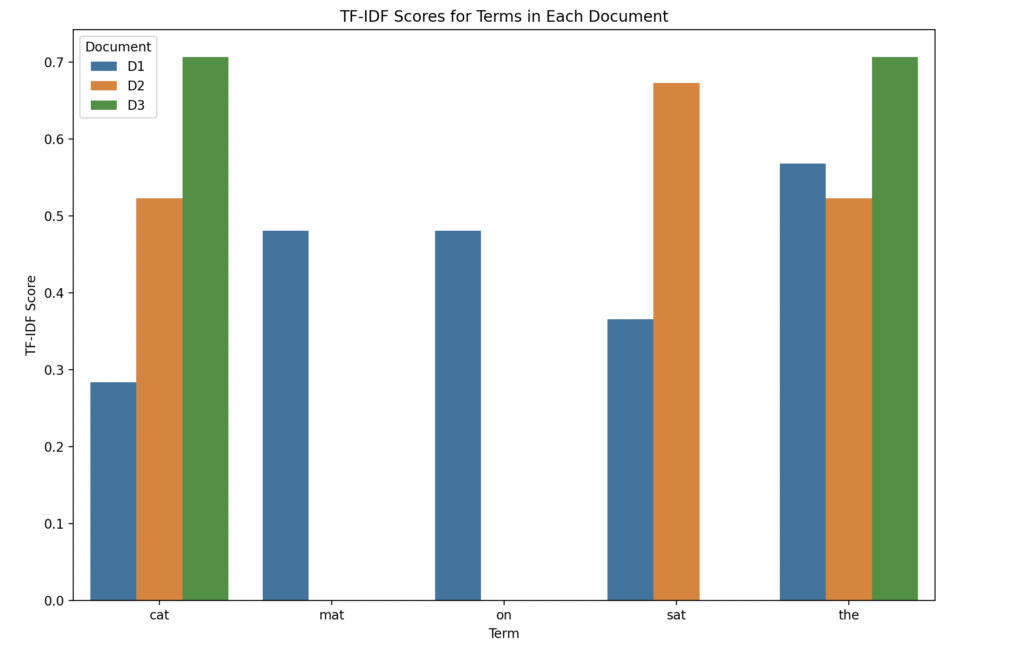
with above code, we get the following output
cat mat on sat the
0 0.284077 0.480984 0.480984 0.365801 0.568154
1 0.522842 0.000000 0.000000 0.673255 0.522842
2 0.707107 0.000000 0.000000 0.000000 0.707107=0.284077^2+2(0.480984^2)+0.365801^2+0.568154^2 = 1.0000
Code to visualize TF-IDF
To visualize the TF-IDF score we can use this code
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.feature_extraction.text import TfidfVectorizer
# Sample corpus
corpus = [
"the cat sat on the mat",
"the cat sat",
"the cat"
]
# Initialize the vectorizer
vectorizer = TfidfVectorizer()
# Fit and transform the corpus
X = vectorizer.fit_transform(corpus)
# Convert the result to a dense matrix and create a DataFrame
df = pd.DataFrame(X.toarray(), columns=vectorizer.get_feature_names_out())
# Add document identifiers
df['document'] = ['D1', 'D2', 'D3']
# Melt the DataFrame for easier plotting
df_melted = df.melt(id_vars='document', var_name='term', value_name='tfidf')
# Plot the TF-IDF scores
plt.figure(figsize=(12, 8))
sns.barplot(data=df_melted, x='term', y='tfidf', hue='document')
plt.title('TF-IDF Scores for Terms in Each Document')
plt.xlabel('Term')
plt.ylabel('TF-IDF Score')
plt.legend(title='Document')
plt.show()
Use Cases
TF-IDF (Term Frequency-Inverse Document Frequency) is widely used in various text mining and natural language processing (NLP) applications due to its simplicity and effectiveness in identifying important terms within documents. Here are some common use cases:
1. Information Retrieval
TF-IDF is used to rank documents based on their relevance to a query. Documents with terms that have high TF-IDF scores for the query terms are considered more relevant.
- Example: Search engines use TF-IDF to index web pages and rank search results.
2. Text Classification
TF-IDF is often used as a feature extraction technique for text classification tasks. It helps in transforming text into numerical vectors that can be fed into machine learning models.
- Example: Spam detection in emails, sentiment analysis, and topic categorization.
3. Document Similarity
TF-IDF is used to measure the similarity between documents by comparing their TF-IDF vectors.
- Example: Finding duplicate documents, clustering similar documents, and recommending similar articles.
4. Keyword Extraction
TF-IDF can be used to extract keywords or key phrases from a document, as terms with high TF-IDF scores are considered important.
- Example: Summarizing articles, generating tags for documents, and content analysis.
5. Content Recommendation
TF-IDF vectors can be used to recommend content based on user preferences and document similarities.
- Example: Recommending news articles, research papers, or products based on textual descriptions.
6. Document Clustering
TF-IDF is used to convert documents into numerical vectors for clustering algorithms like K-means, enabling the grouping of similar documents.
- Example: Grouping customer reviews, organizing a large corpus of text into coherent clusters.
In the coming blogs, we will read about BM-25 (Best Matching 25), and then about ReRanker, which are important components to improve the RAG performance