Introduction
In distributed systems, maintaining data consistency across multiple systems is a challenging task. One common problem that arises is the dual write problem, where updates to multiple data stores must be performed atomically to prevent data inconsistencies. In this blog post, we’ll explore how to tackle the dual write problem using the outbox pattern in conjunction with Apache Kafka.
Understanding the Dual Write Problem
The dual write problem occurs when data needs to be written to multiple systems, and ensuring consistency between them becomes crucial. For instance, imagine an e-commerce application where an order is placed and data must be simultaneously written to a database and a messaging system like Kafka for further processing. If one write succeeds but the other fails, data inconsistency arises.
Introducing the Outbox Pattern
The outbox pattern is a proven solution to the dual write problem. It involves persisting data that needs to be written to multiple systems in a local outbox table within the same transaction as the primary write operation. This decouples the primary write from the actual propagation, reducing the risk of inconsistencies. Once data is safely stored in the outbox, a separate process reads from it and propagates the changes to the target systems.
Implementing the Outbox Pattern with Kafka: To integrate Kafka into the outbox pattern, we’ll use it as the messaging system for propagating data changes. Here’s how we can implement it:
- Design the Outbox Table: Create an outbox table in your primary database to store events or data changes. Include fields like ID, timestamp, payload, and status.
- Write to the Outbox: Upon performing a write operation to the primary database, insert the relevant data into the outbox table within the same transaction.
- Process the Outbox Entries: Implement a separate process, often referred to as the outbox processor, to read from the outbox table periodically. This process reads pending entries and publishes them to a Kafka topic.
- Consume and Process Kafka Messages: Set up Kafka consumers to consume messages from the designated topic. These consumers process the messages and perform the necessary actions in the target system, ensuring data consistency.
CREATE TABLE outbox (
id INT AUTO_INCREMENT PRIMARY KEY,
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
payload JSON NOT NULL,
status ENUM('pending', 'processed') DEFAULT 'pending'
);
Write to the Outbox: When you need to perform a dual write operation, insert the data into the outbox table within the same transaction as the primary write operation. This ensures atomicity.
START TRANSACTION;
-- Perform primary write operation
INSERT INTO your_primary_table (column1, column2, ...) VALUES (value1, value2, ...);
-- Insert into the outbox
INSERT INTO outbox (payload) VALUES ('{"id": 123, "data": "your_data"}');
COMMIT;Process the Outbox Entries: Implement a separate process (outbox processor) that periodically reads from the outbox table and propagates the changes to the target systems. This process should be idempotent to handle failures and retries correctly.
Mark Entries as Processed: After successfully propagating the changes to all target systems, update the status of the outbox entries to ‘processed’ to prevent them from being processed again.
UPDATE outbox SET status = 'processed' WHERE status = 'pending';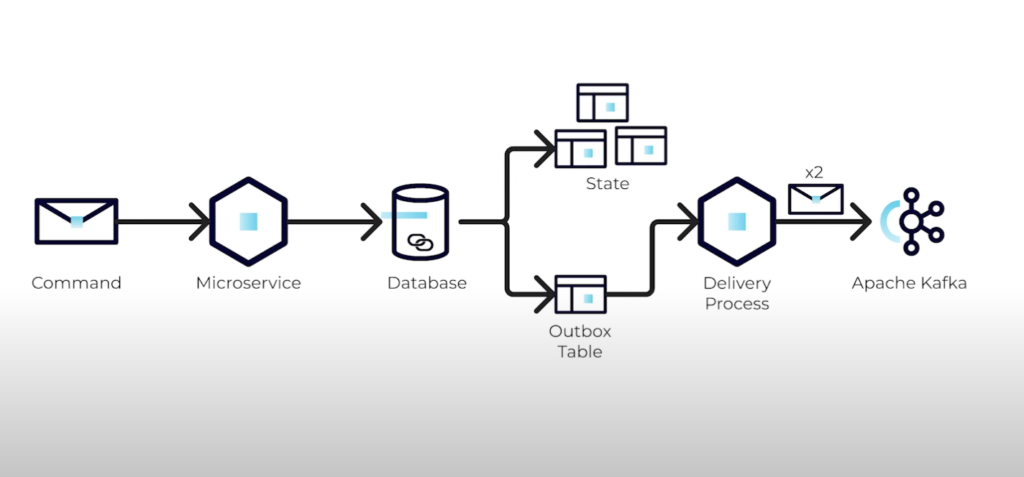
As the delivery process can try multiple times to push the message to Kafka, With this, we will have at least once delivery and we need idempotent processing logic on the consumer side. Idempotent processing ensures that the same message can be processed multiple times without causing unintended side effects.
Challenges and Considerations:
- Serialization and Deserialization: Ensure proper serialization and deserialization of data between the outbox table and Kafka messages.
- Monitoring and Error Handling: Implement robust monitoring and error handling mechanisms to detect and handle failures in the propagation process.
- Message Ordering: Depending on the application requirements, you may need to consider message ordering guarantees provided by Kafka.